
A First Principles guide to Data Availability: Part 2
Understanding the rapidly evolving landscape of non-Ethereum DA solutions

This article is part 2 in the Data Availability series, for part 1 see here
Preface
Data Availability (DA) has been a widely discussed term in Web3 now for the last 12-18 months with the explosion in modular design and rollups in the Ethereum Ecosystem. In Part 1 of this series we explored the first principles of Data Availability with a focus on the core components of the system and how it has historically functioned on Ethereum before the wave of new solutions emerged. In particular we spent time understanding how different types of rollups (Optimistic vs. ZK) interacted with Ethereum-native DA at a granular level.
Part 2 shifts focus to the alternative DA layers, the implications behind their design, and makes explicit the tradeoffs each makes. Since the original article we have seen the launch of EIP-4844, EigenDA and Celestia which are analyzed in this article as well.
Contents
Part 1: Bottoms-up look at data availability and why it’s needed
Context on Ethereum’s rollup-centric roadmap
Deep dive: How rollups generate and utilize data on the Ethereum L1
Data availability for Optimistic rollups on Ethereum
Data availability for ZK rollups on Ethereum
Ethereum-native Data availability scaling
Part 2: (This article) Deep dive into non-ETH data availability solutions
Alternative non-Ethereum Data Availability solutions
**Deep dive on Fraud and Validity proofs
Data Availability vs. Data storage
Part 3: Where the future is headed for data availability
The current state of Data Availability
A few predictions on how DA evolves
Potential future areas of exploration
**Section moved to standalone article
Recap: why do we need alternative DA solutions to Ethereum?
In Part 1 we covered how Data Availability (DA) provides a guarantee that data is supplied to proof systems (ZK or Optimistic) that settle rollup transactions. As of now most DA utilizes the native solutions in Ethereum mainnet (calldata and EIP-4844 space), however cost to store on Ethereum is prohibitive, historically accounting for up to 80% of the cost of operations. This is due to limitations in the supply of DA bandwidth because of Ethereum’s limited blocksize and the competition for this blockspace with non-DA transactions. If we believe that web3 will continue to grow in transaction volume, new DA solutions will be needed to maintain security for rollups without being cost prohibitive.
We have already seen improvements to the cost of DA layers via the Dencun upgrade (Mar 13, 2024) which included EIP-4844, introducing a separate blobspace in Ethereum that has introduced greater storage capacity. This is the beginning of what we can expect to be a supply / demand game that will play out as web3 expands and new solutions
Where does the demand for DA bandwidth come from?
We’ve established that more DA supply is needed to meet demand, but it’s important to monitor what is truly driving this demand. “Data availability” is attached to a lot of buzzwords - AI, distributed compute, ZK - but the requirements and willingness to pay for DA varies by end user. Data availability creates value by supporting a few valuable functions:
Transaction confirmations
Recovering rollup state
[If it includes consensus] Sequencing of data
DA is more important for higher-valued transactions where the value of fraud is higher and more security is needed (e.g. large Defi tx). Other end markets may choose different sets of tradeoffs in selecting DA as options become available.
Choosing a DA solution comes down to a few specific design tradeoffs::
The volume of transaction data
The value of the individual transactions
The cost sensitivity / risk tolerance tradeoff of the user
For example a DeFi chain may rely on Ethereum for DA in order to guarantee the highest security for it’s transactions, at a higher cost. Alternatively, a gaming client may require higher throughput transactions that are on average lower value, which could be a poor fit for the expensive Ethereum native DA.
Alternatives to Ethereum Data Availability
In Part 1 we covered the design and process for “native” data availability on Ethereum and the limitations of that system that have brought rise to alternatives. To understand the landscape of DA and where it’s likely to move next, we need to understand and compare these systems against each other, in particular across the dimensions of:
A brief overview of the modular blockchain paradigm
Ethereum pioneered the concept of a programmable blockchain, which necessarily enshrined all functionality into a single monolithic stack. As the industry has evolved over the last 2-3 years towards a rollup-centric roadmap, the stack has been re-imagined into a more modular architecture which separates core functionality into different layers.
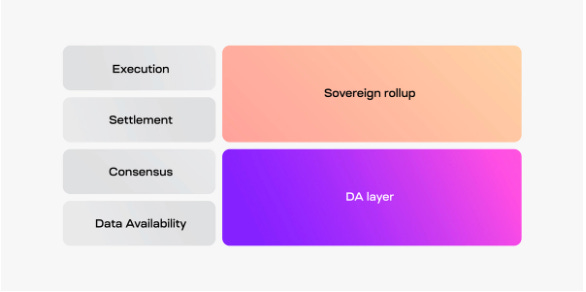
The Modular Blockchain thesis separates the monolithic chain architecture into 4 modular ‘layers”:
Execution: Calculating and applying updates to chain state
Settlement: Finalizing the transactions e.g. through challenges, proofs or arbitration
Consensus: Agreeing on the transactions to be included in a block and their order (sequencing)
Data availability: Holding the transactions and making it available to the settlement layer
The initial rush of Data Availability projects were touted as standalone DA layers (e.g. Celestia, Avail), when in reality data availability is a component of a much larger vision. To over-simplify, we’ll categorize Data Availability solutions based on which parts of the modular stack are enshrined into their system:
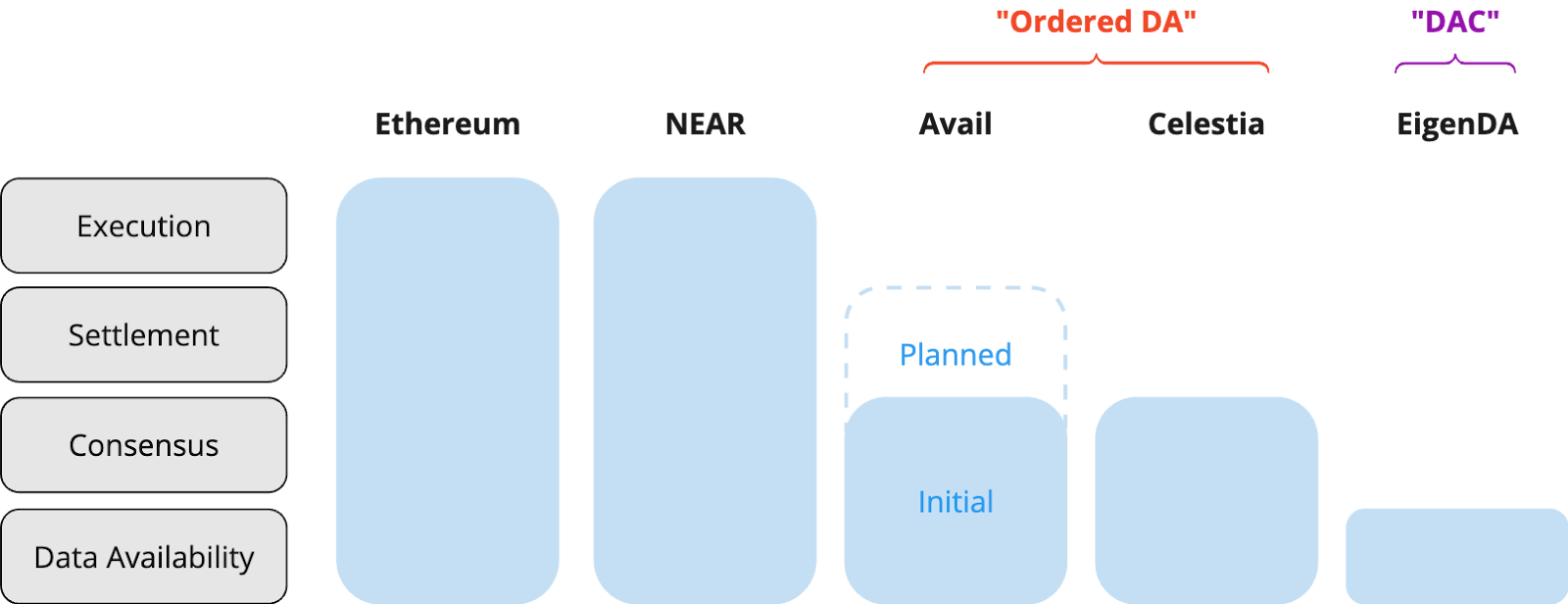
*Thanks to Celestia docs for inspiration
In Part 3 we will dive deeper into the implications of these choices, but an interesting theme will be understanding where value accrues over time. Adding more components to the core DA layer introduces inefficiencies to the DA layer itself, but can enable additional security and functionality for these projects.
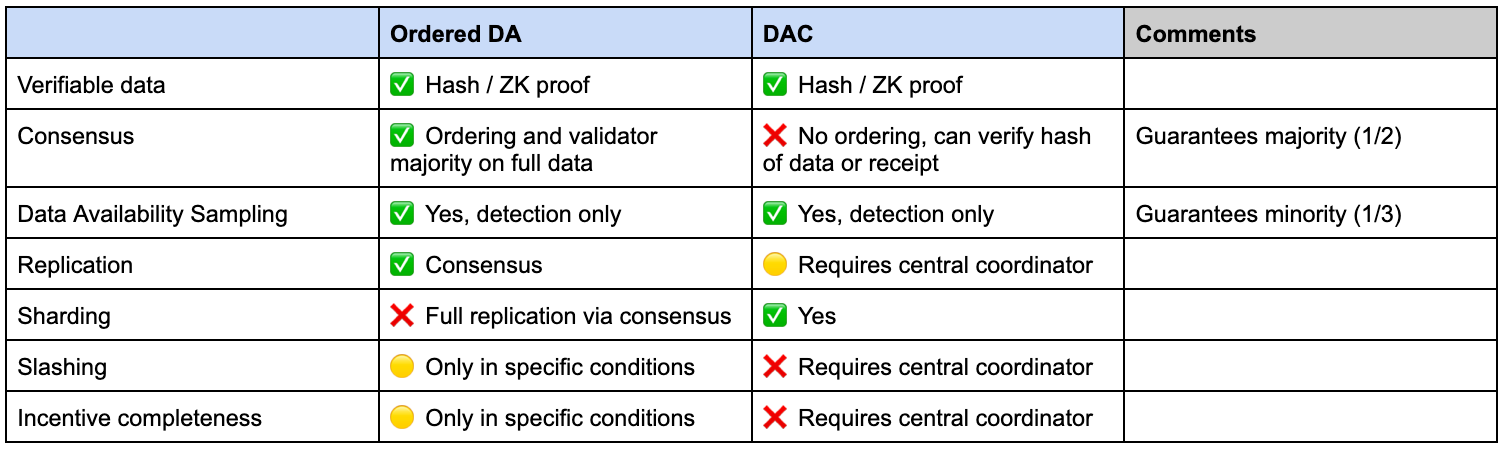
For simplicity in this piece we’ll call systems with DA + Consensus “Ordered DA” and Data Availability standalone solutions “DAC” for Data availability committees.
Design
TLDR
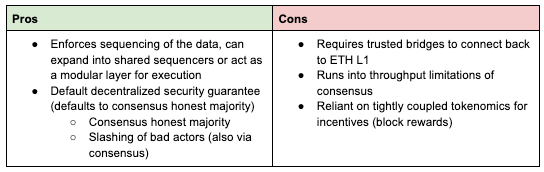
Ordered DA faces inherent scalability of putting data through consensus, but (e.g. through DAS) more effectively than DAC.
DACs provide higher throughput / lower cost but are unable to do ordering and have lower security guarantees / more centralization
Most DA solutions are multi-purpose, acting as a feature in a broader system
Celestia looking to host rollups / sequencing
Avail looking to do proof aggregation
EigenDA is driving demand for AVS / EIGEN locking
NEAR, SUI are driving blockspace demand
Ordered DA (Celestia, Avail)
Celestia is the most well known “Ordered DA” solution and a pioneer of the modular stack. Avail’s initial product is a similar solution originating from the Polygon ecosystem, but makes different choices in its design (outlined below). These solutions provide data availability AND consensus by ensuring availability of data submitted by rollups and providing guarantees of proper ordering / creation of blocks.
Source: Celestia docs
However this design does not enforce execution and settlement - it cannot verify that data is correct and facilitate any proof to support this claim. This implies a few tradeoffs:
Ordered DA can order data and generate blocks of transactions
These solutions CANNOT verify the validity of those transactions, only correct inclusion
Proofs and adjudication are performed at the Ethereum L1 (or another execution / settlement layer)
As outlined in Part 1, data availability is part of a broader process meant to secure the transactions of the rollup, lets walk through in detail to understand the nuances of what a non-Ethereum native DA implies:
1) Publishing - generation of a batch of data from the rollup and submission to the DA layer
2) Storage - bytes of data are committed to memory in some part of the system
3) Verification - full data is proven to be accessible (e.g. light client sampling)
4) Settlement - data is retrieved as part of the proof process and proofs are executed to confirm the block
5) Pruning - data is removed from DA layer to archival nodes or deleted
1) Publishing
In native DA, the full batched data is submitted by the rollup batcher, by adding it to the ETH L1 calldata via a contract on the L1. In the case of alt-DA only a commitment to the batched data (merkle root or KZG) is submitted to the L1 which can reference / verify data on the DA layer, while the full data is sent to the Alt-DA layer.
Once data has passed to the Alt-DA layer, it is pre-processed via erasure encoding and other methods to heighten security and improve performance of data availability sampling (DAS). Additional pre-processing (e.g. namespacing, sharding) may be applied, then this encoded data is then included in a transaction queue and added to a block.
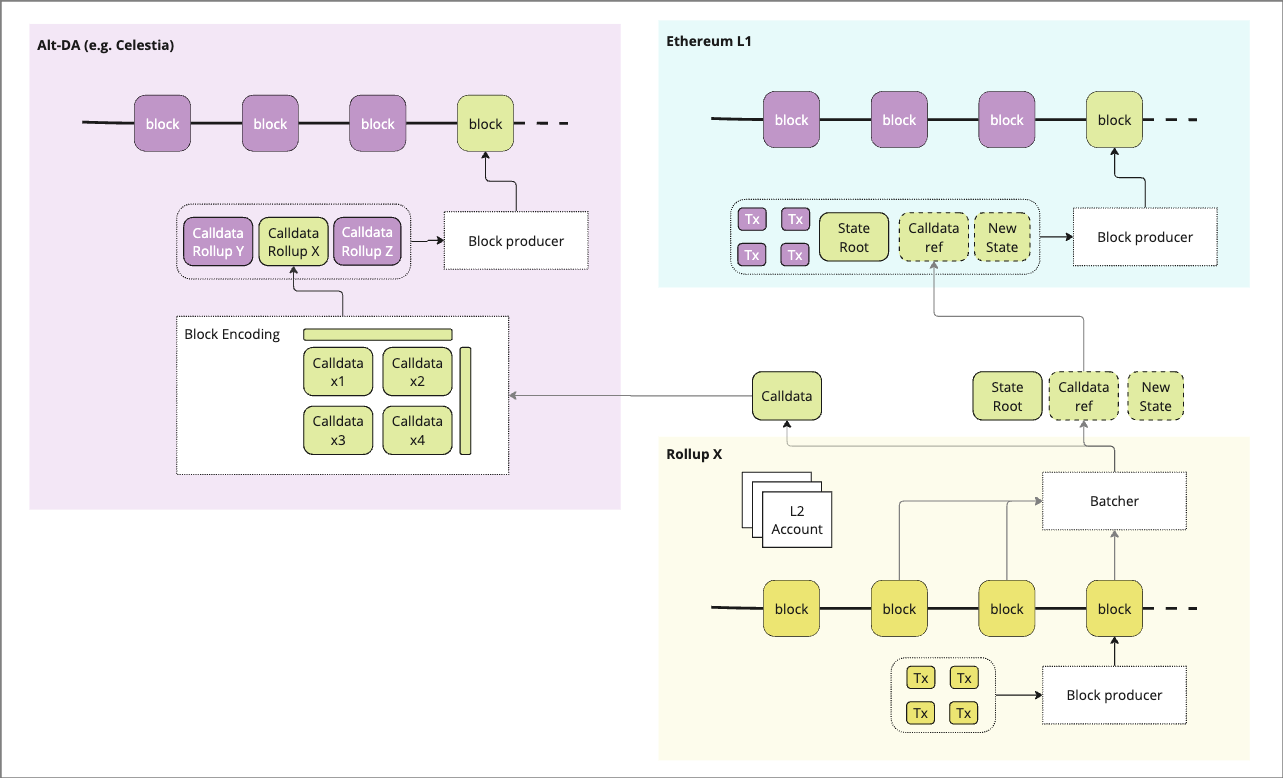
2) Storage
The encoded transaction is then packaged in a block by the block producer and submitted for consensus. The validator set will reach consensus and the block becomes submitted to the chain, upon which time there is typically a proof submitted by validators or a receipt of storage locally that is aggregated and submitted to the ETH L1 to prove that data has been stored in the DA layer. Critically, the data sent from DA layer to ETH L1 must be via a trusted bridge, which may be controlled by a multisig, data availability committee etc (e.g. celestia’s blobstream). These receipts typically include a merkle root or ZK proof that can be proven against the Rollups L1 submission.
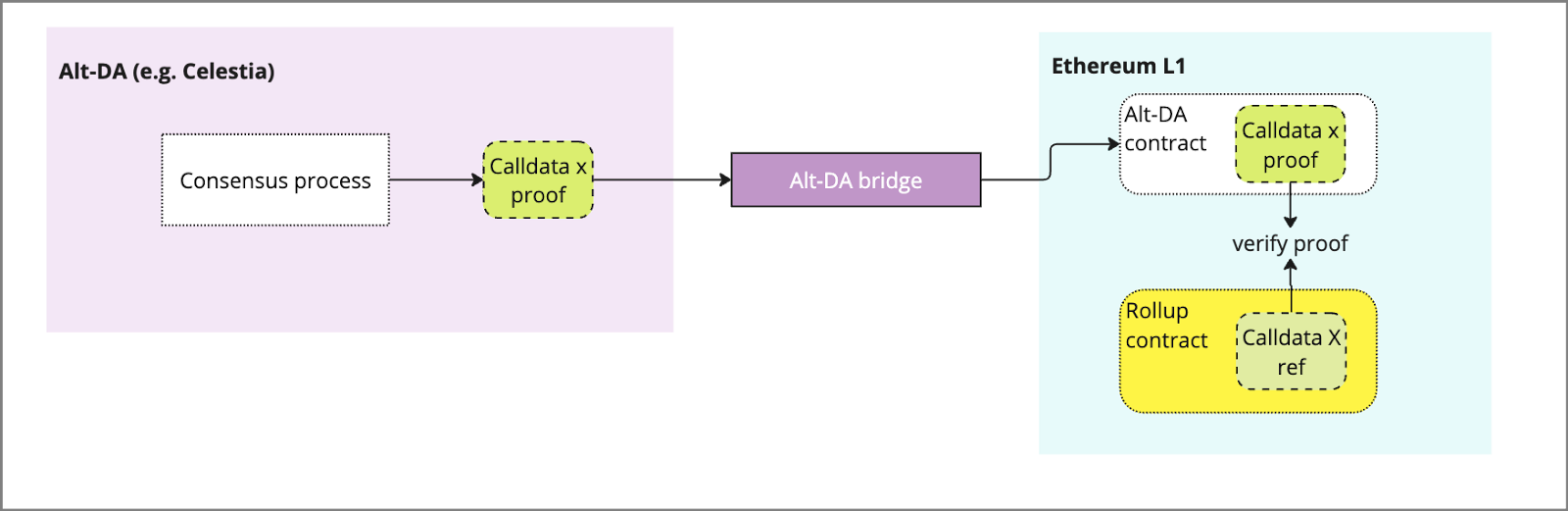
The Alt-DA bridge serves as the conduit between the DA layer and the L1 contract, serving proof that data has been made available. This can be implemented in various forms:
Multisig
Data Committee
Celestia Blobstream (leveraging consensus)
References:
3) Verification
After data has been included in a published block, data availability sampling (DAS) can be used to provide additional security up to a 2 / 3 malicious validator set. This is accomplished by light nodes sampling and verifying slices of a block against the 2D encoding that was added during the pre-processing step:
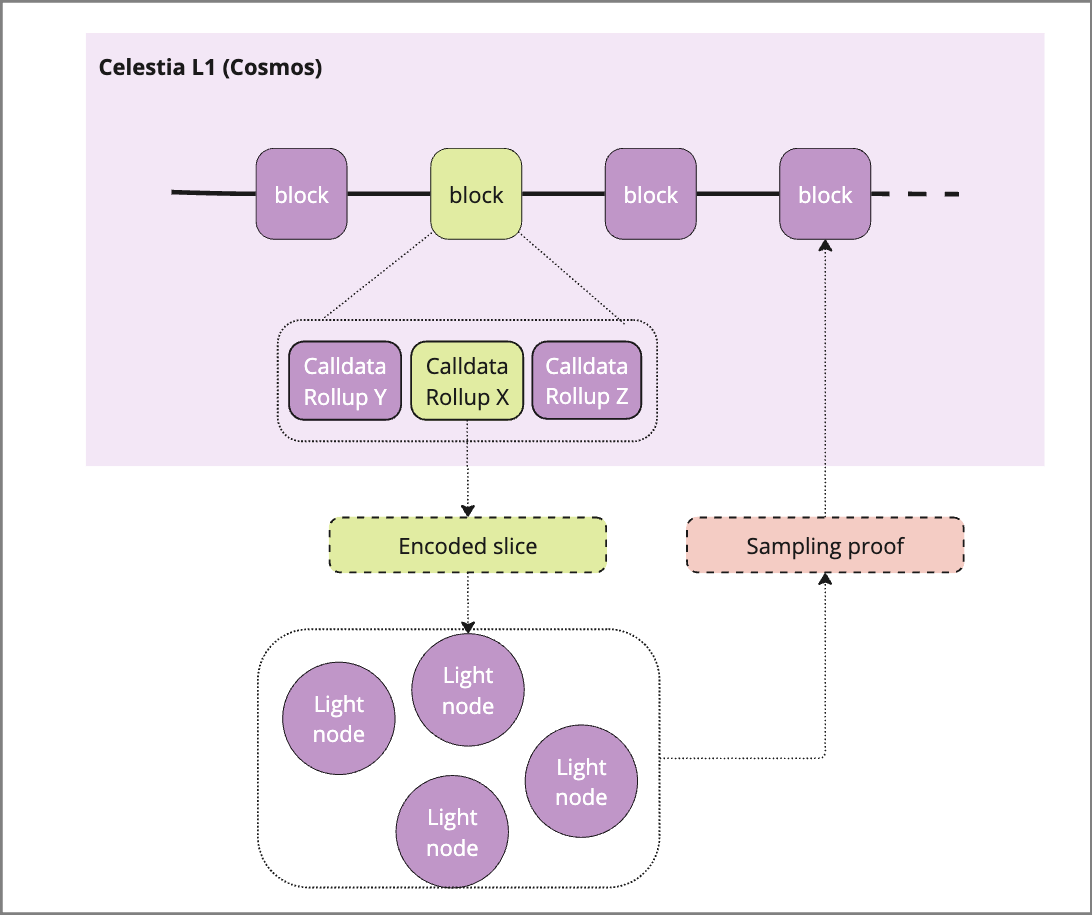
A light node requests a sampling task
An orchestrator passes an encoding slice of the block at hand to the light node
The light node verifies that the data matches the error-correcting code
Light node returns proof of the data availability
Sufficient numbers of slices are sampled and returned to prove that the block can be recovered
4) Settlement
To confirm the transaction, a prover follows the reference to the data in question that was submitted to the L1 to pull the required data via a trusted bridge. Because the Ordered DA solutions do not include settlement, this must take place at the L1 (or other sovereign rollup). Depending on the type of challenge (Fraud vs. Validity) the requirements may change for data transmission from the DA layer.
If the proof is verified, the transactions are confirmed
If the proof catches fraud, the transaction data from the DA layer can be used to reconstruct the state
This data must be served by a validator node when requested by a prover, which ideally implies that the requestor is indistinguishable from a light node.
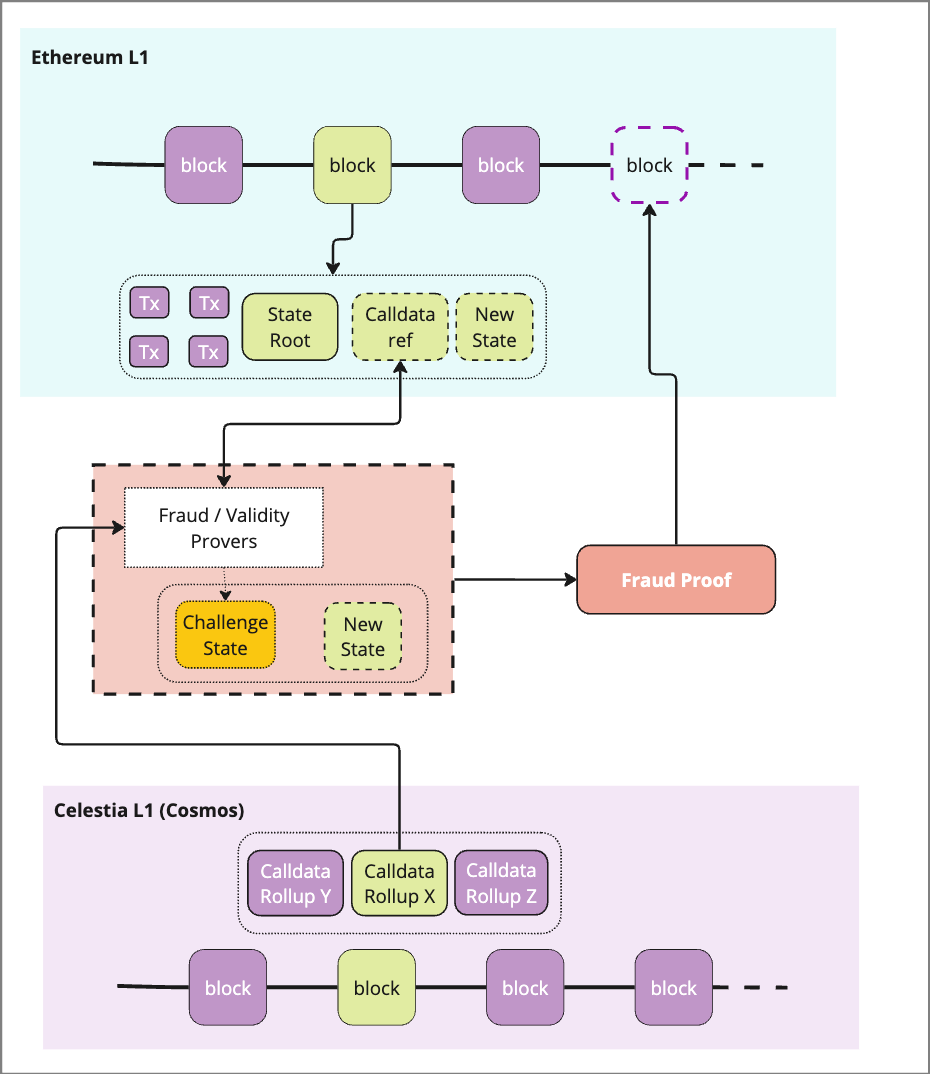
5) Pruning
Once a block has been verified, the transaction data stored on the DA layer is no longer needed for the verification process. DA layers typically only hold data for 7-14 days (challenge period), after which the data is pruned or moved to an archive node.
Where Celestia and Avail DA differ
Celestia and Availa both have plans for a Data Availability layer, but introduce small design differences in their initial implementation:
Merkle vs. KZG commitments - Celestia currently utilizes merkle roots for it’s commitments to the L1 while Avail uses KZG commitments that offer more performant verification. For more details, see Dankrad’s post on KZG commitments
Consensus - Celestia is Cosmos-based and uses tendermint (100 validator max), Avail is polkadot-based and uses GRANDPA consensus (1000 validator max)
Data bridge - Celestia utilizes a ZK-bridge (blobstreamX), Avail uses a trusted set of actors (currently).
More importantly, Avail has laid out plans to become the unification layer for web3, which will add a settlement layer on top of the core DA layer in a phased plan:
DA Layer
Nexus - proof aggregation and sequencer selection allowing for cross-ecosystem settlement
Fusion - leverage multiple tokens as collateral
Summary
Ordered DA includes consensus in the DA system, which increases security and potential features, but introduces fundamental limitations of scalability. Consensus algorithms are not reliable beyond 1000 validator sets and introduce limitations on throughput and finality. Block size can be expanded to increase throughput (e.g. Solana) but this increases hardware requirements and thus, centralization.
Data Availability Committees
1) Publishing of data
Similar to Ordered DA, a proof of data is submitted to the L1 in place of full data, which acts as a reference to the full data held in the DAC. A trusted bridge is used to relay the calldata from the rollup batcher to the DAC, or in the case of EigenDA a contract held on the L1. The initial ingestion step of the data from the L2 needs to go through an orchestrator like service that ingests the block.
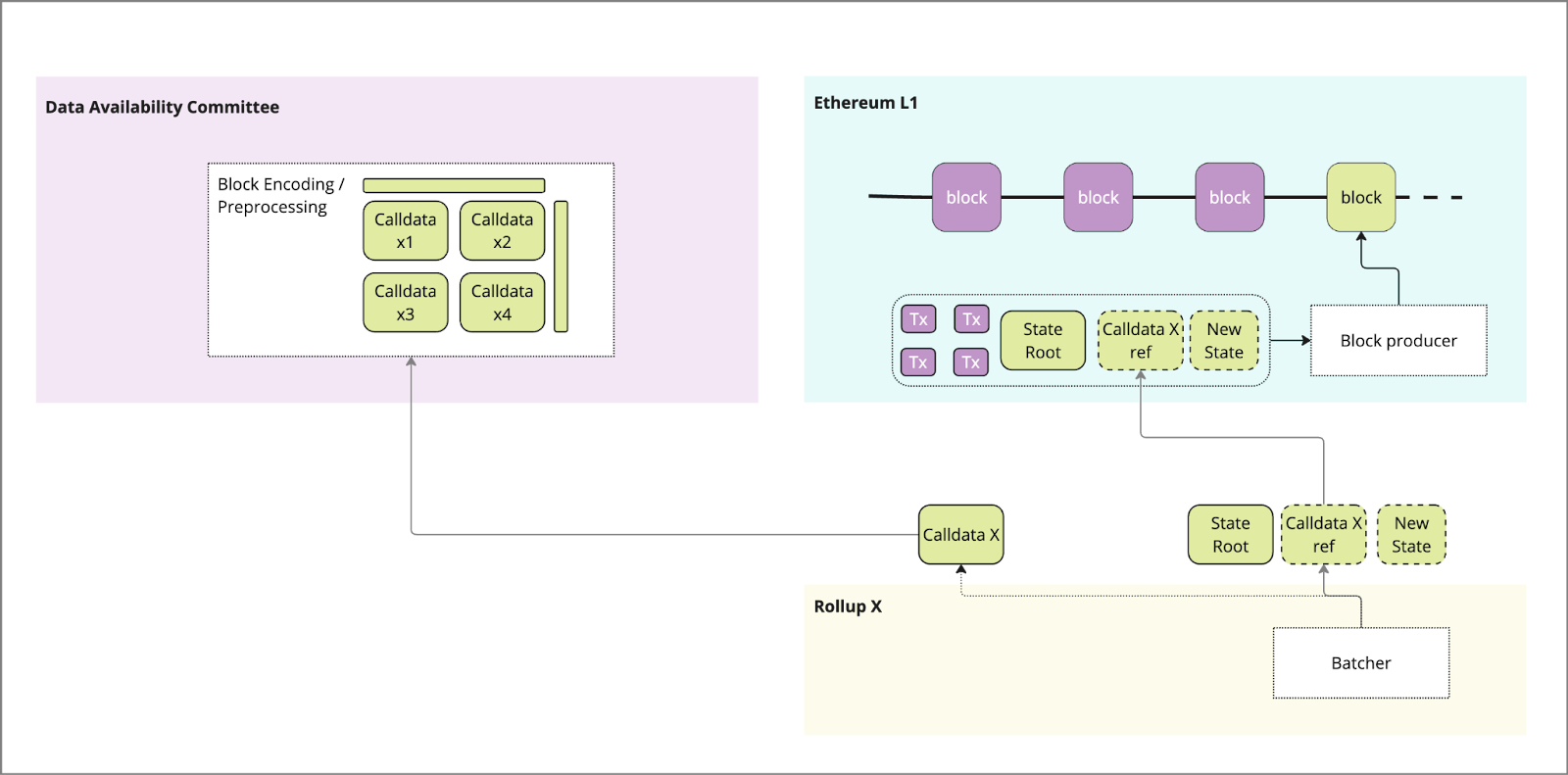
The DAC orchestrator contract performs any pre-processing (e.g. erasure encoding or sharding) and prepares the data for storage with the eligible DAC nodes.
The DAC process of pre-processing DOES NOT take place “on-chain” in a block-building process, which may introduce centralization.
2) Storage of Data
This is the primary difference between Alt-DA layers and DACs. Rather than the data being included in a consensus process, the data is instead passed to a service that allocates it to the DAC members. This may be through sharding or replication, and in some cases the data may be erasure encoded for additional security.
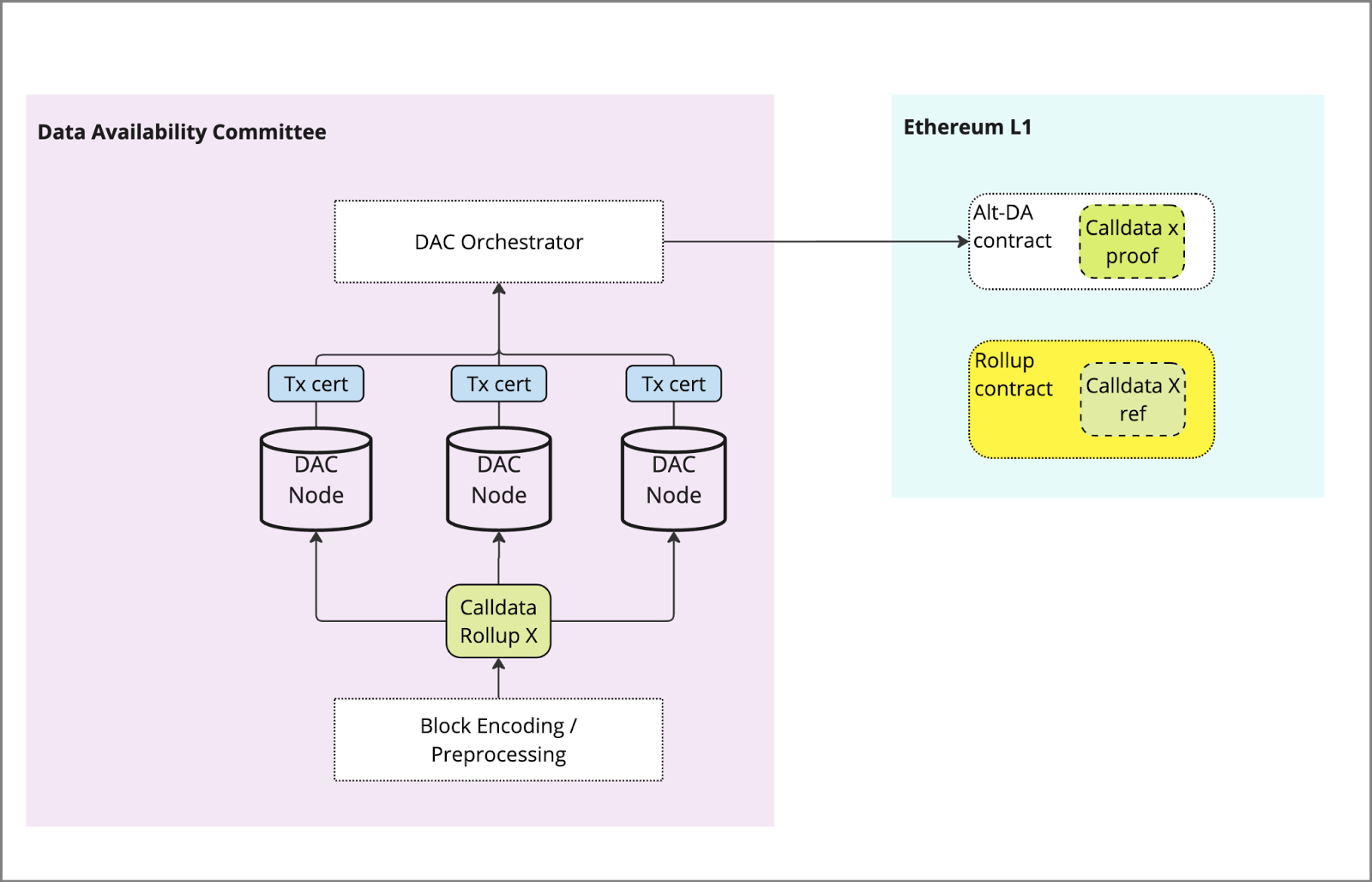
Once data is stored, DAC nodes responsible send confirmation and a Hash / signed cert attesting to data storage. This signature and ID of DAC node is submitted to a contract on the L1 and verified against the root submitted by the L2 in (1)
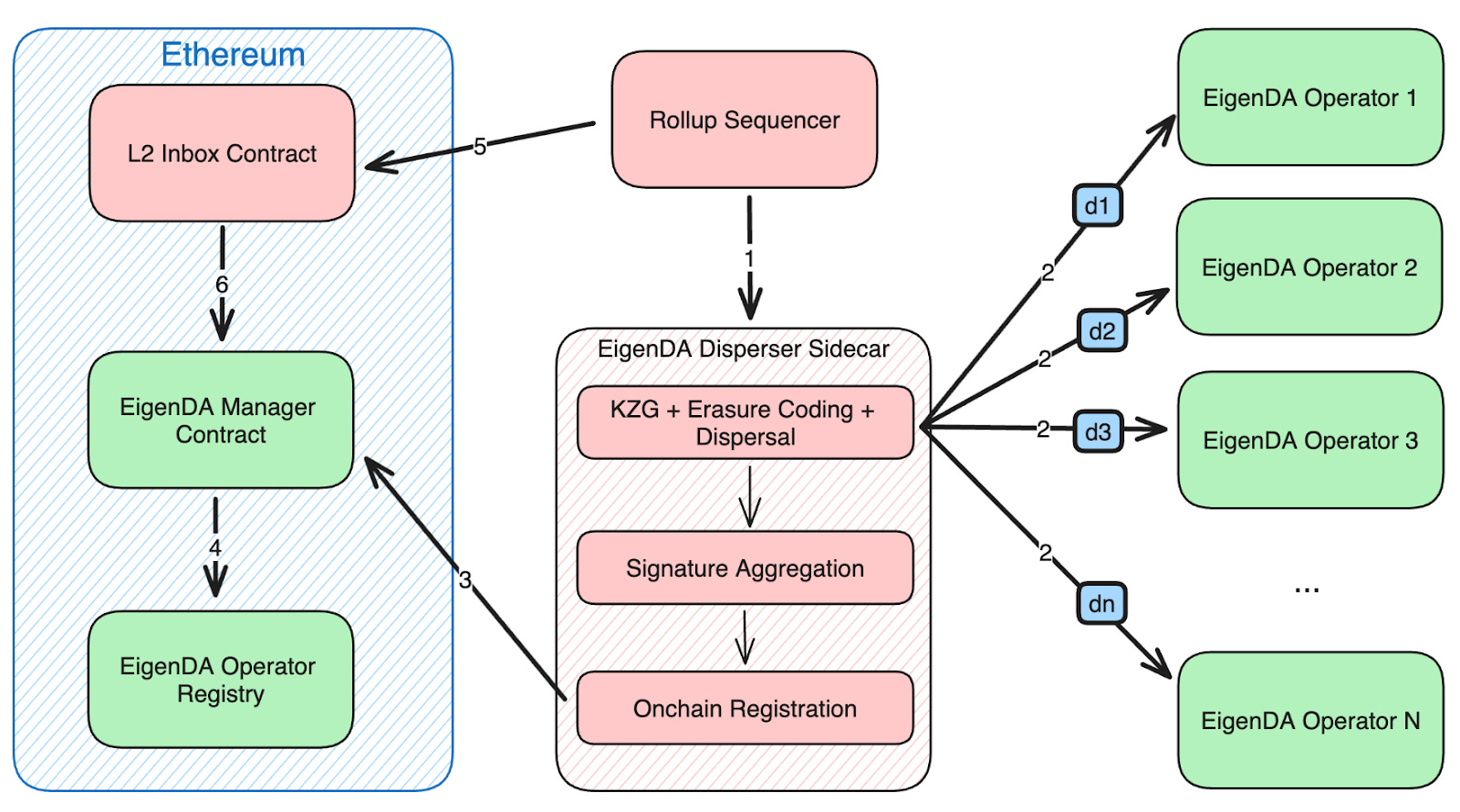
Source: EigenDA docs
3) Verification of integrity
DAC’s can guarantee via a trusted set of providers or implement additional steps such as data availability sampling (to an extent) in order to verify that the data has been made available. This is typically done via operators submitting proofs of the data they possess and being subject to potential slashing conditions if malicious behaviour is found.
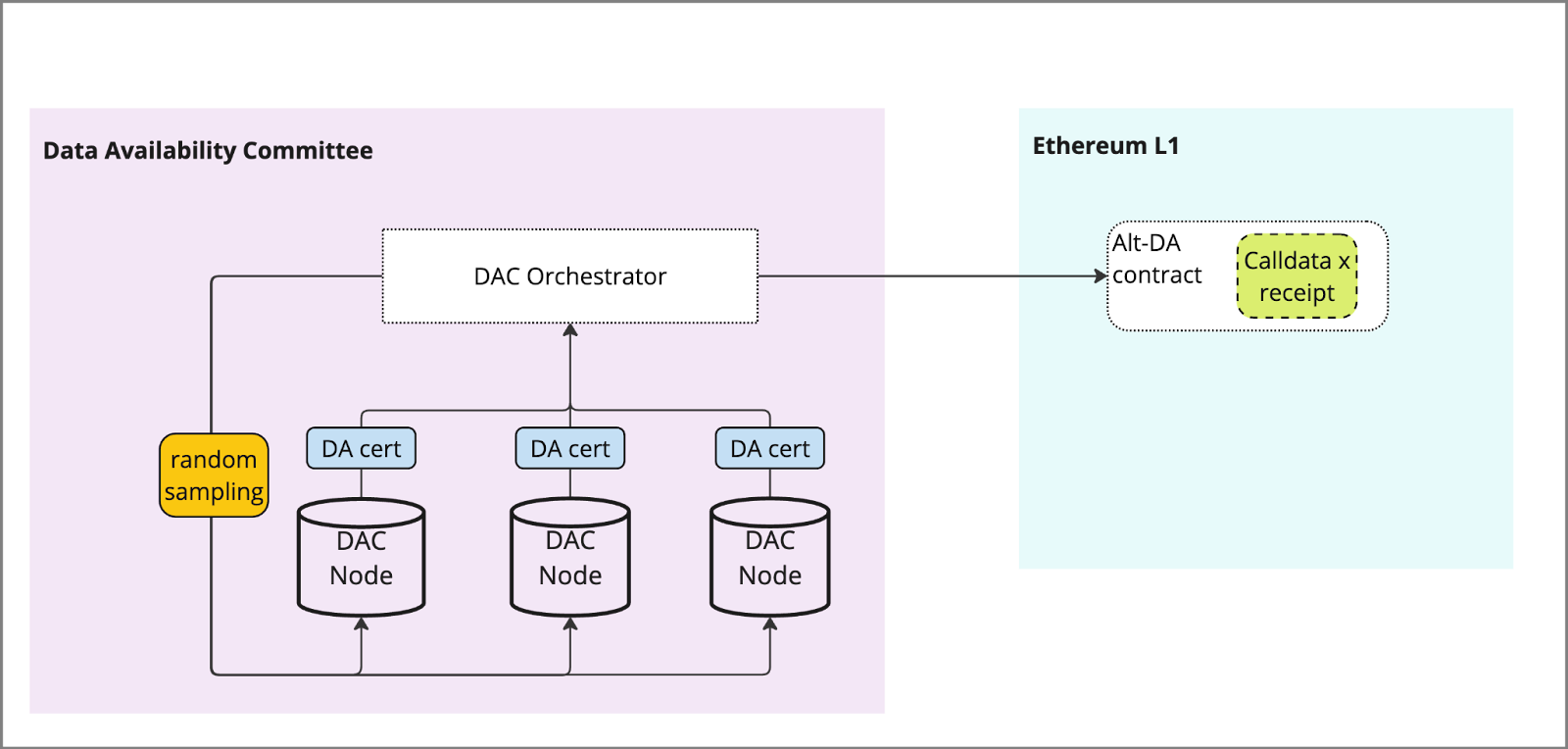
Some variations include:
(Shown) Central orchestrator used to facilitate random sampling of data as a gateway, indistinguishable from regular retrieval
Light nodes used to sample the nodes and submit proofs to the orchestrator or an L1 contract
In order to enforce the slashing conditions on any node, it is likely a chain is needed to utilize consensus, otherwise central orchestration is needed.
4) Finalization process
Prover finds the reference (KZG or merkle root) similar to alt-DA, requiring one or more members of the DAC to provide the data in time for the prover to generate a proof finding the block valid or not.
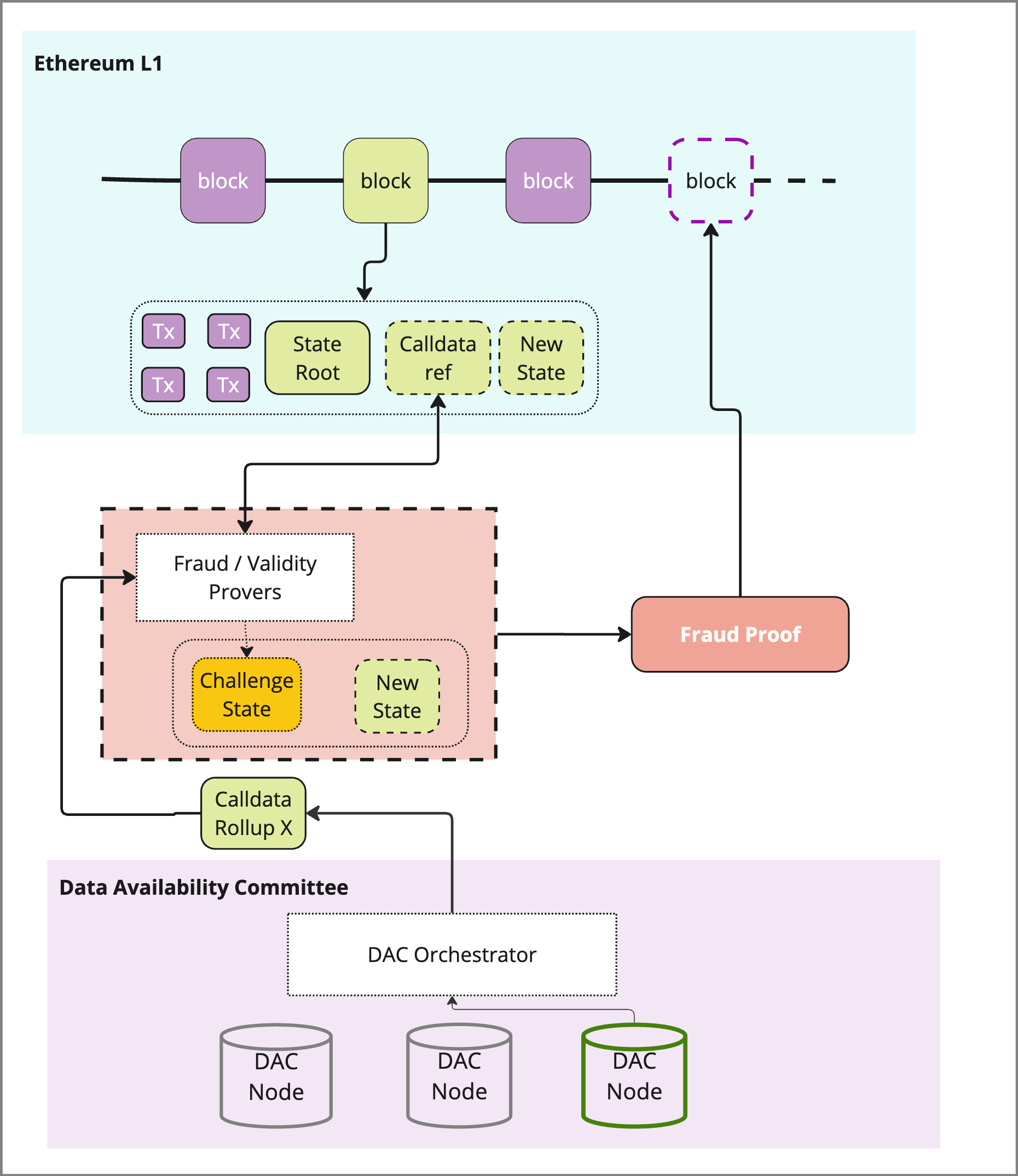
5) Pruning
In the case of DAC’s the guaranteed storage time looks more like a storage contract where storage is required for X amount of time or until conditions are met. Right now there is no incentive to hold beyond the time which the operator is subject to slashing conditions
Differences between DAC solutions
EigenDA is the newest but likely most visible - it functions as an AVS (actively validated service) run by the Eigenlayer team as a first product in their portfolio of AVS products. EigenDA utilizes the Ethereum Validator set to restake ethereum economic capital towards securing the data availability layer. The central contract and related services are also on Ethereum, which presents the opportunity to impose slashing conditions directly on Ethereum mainnet (not yet deployed).
Other DAC’s such as Arbitrum and ZKPorter are in-housed solutions run by the rollup host themselves - in both cases via a host of trusted, known participants like Infura, their own foundations, etc.
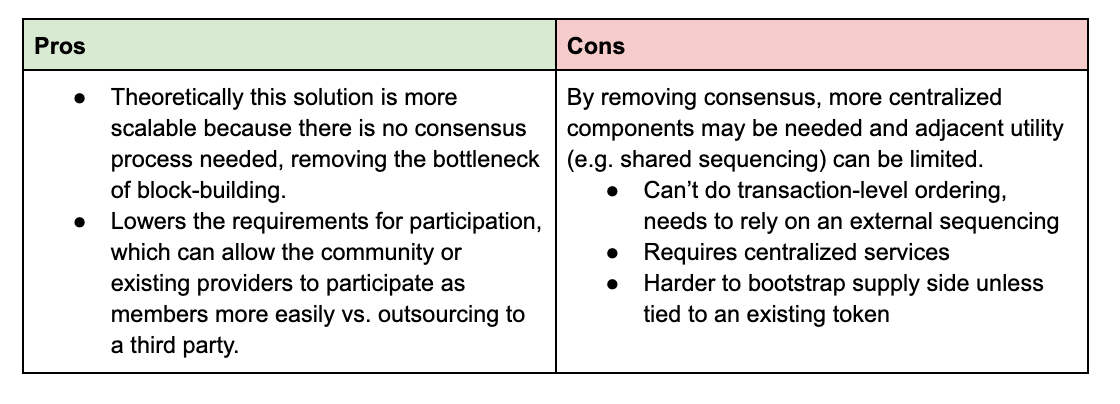
Summary
DACs provide higher scalability and lower cost, but at the tradeoff of a less theoretically secure system.
Security
TLDR
Security of current DA solutions is mainly predicated on the economic security maintaining the system plus the presence of a fully objective slashing mechanism
Majority consensus is the strongest guarantee
DAS and other light node sampling can create an “honest minority” where 1/3 of validators can guarantee safety, assuming slashing conditions are correct
Enforcing proper slashing is still an area of significant development, without it DAS system are not providing any additional security
DA by itself does not create security, there must be consensus / settlement
Discourse around DA solutions has revolved around the “security” relative to core Ethereum. Ultimately many of these security concerns boil down to an assessment of “cost of fraud” against its potential upside. Different DA architectures offer tradeoffs of security vs. performance - it should be the decision of the rollup to decide what the right design tradeoffs are.
To recap, DA is a key component of the process to provide security for transactions on any rollup anchored to the Ethereum L1, which provides:
Guard against fraudulent transactions in the L2
Allow any participant in a rollup “credible exit” to withdraw their funds to the L1
Restore previous state of a rollup in case of failure
As outlined above in the design section and Part 1, DA is a component in a process that starts with rollups submitting data to a DA layer and ends with a verified proof on the L1 that provides the guarantees above. But what are the specific attack vectors that DA guards against?
Withholding attack: Data is withheld from provers who need it as input to Optimistic / ZK proof process validating transactions
Censorship: Certain transactions (e.g. from a specific address) are deliberately withheld from blocks
Malicious sequencer: Sequencer censors or alters data
Malicious encoder of data: Block producer incorrectly encodes the data (e.g. erasure encoding) causing light node sampling to fail
DA solutions provide different levels of guarantees against the above depending on their model, which is achieved with a few pieces of great technology in the web3 world:
Cryptographic verification of data and transactions
Decentralized consensus on components of the DA layer (data, ordering, receipts)
E.g. majority of economic security agrees on a set of transactions and ordering
Erasure encoding and Data availability sampling
Creates an honest minority assumption - as long as encoder is trusted, only one honest node is needed to get the data
Replication / sharding of data
Slashing of bad actors
Complete cryptographic incentives for desired activities (increasing cost of fraud)
While all of these guarantees seem great on paper, there are many practical considerations when comparing theoretical guarantees to implementation in reality. Most of these systems are early in their lifecycle, and are by nature volatile and constantly changing - this requires constant attention to ensure security guarantees are maintained for the end user. Practically, this also means that a simpler and more stable yet “theoretically suboptimal” solution may be a better fit for user needs.
$$ stake securing consensus
Ultimately most of the architectures rely on an explicit or implicit consensus among a set of nodes, where economic stake at risk of slashing is a proxy for security. Users need to understand the stability of the validators / stake securing the consensus over time - how many nodes are active, total economic value given price fluctuations, concentration, etc. Especially while these networks are nascent, nodes may be participating to gather rewards but drop off after airdrops / price deprecation (true for both DA chains, but also DAC’s incentivizing off-chain nodes).
Key DA aspects to monitor
Overall stake / active security in network
Tokenomics changes - inflation, implications for node profitability
Node concentration
Light node volume and sampling efficacy
Erasure encoding and DAS provide additional guarantees to achieve “honest majority” security assumptions under the condition that a sufficiently large group of (honest) light nodes can sample a published block to recreate the block in case of withholding.
However there are many open research questions around the efficacy of light nodes. Scalability of light node networks relies on p2p protocols which are not proven to be performant at scales required to reach hypothetical GB+ throughputs. Slashing via light node proofs is still not mature, as 1:1 relationships between retrievals of data are subjective relative to network delays / faults etc. “Partial withholding attacks” can lead a light node network to falsely declare receipt of data and limit security to a 1/3 minority of nodes.
Finally, light node networks are un-incentivized and vulnerable to sybil attacks which can spam RPC providers, overload DHTs, and provide false confirmations to the network.
Key DA aspects to monitor
Sufficient number of light nodes are needed to guarantee full sampling per block
Monitor for light node sybil attacks
Account for submitted DAS proofs
Slashing conditions
Malicious activity such as the list of attack vectors above needs to have negative consequences enforced typically via slashing of staked collateral. This requires the DA system to have objective / scalable slashing built in that can be enforced at the individual node level. In many cases this slashing is enforced via a central orchestrator which works against the decentralized guarantees of the solution
Key DA aspects to monitor
Has slashing been implemented
How complete and effective are the slashing measures
What % coverage for slashing (e.g. all transactions or just a portion)
Incentive completeness
A more subtle long-term threat to DA systems as they scale is the emergent effects of their incentive model, specifically which actions have incentives that align the nodes to the aims of the network. One such example is retrieval of data - while DAS can reconstruct a block when working correctly, it is not an economically feasible or performant way to provide information to a set of provers. Later-stage networks have shown that retrieval bandwidth / operations are expensive and nodes will not serve unless explicitly incentivized.
Key DA aspects to monitor
Serving full data to a fraud prover must look similar to DAS
Needs more work to make a DAS sampling node indistinguishable
Application data tracking
Applications using DA layers should track their data from end to end to ensure the data is unaltered, and it has been passed through the various systems and successfully finalized on the L1. Breakdowns in data submission across the multiple integration points in these systems can lead to dropped transactions and security threats.
Key DA aspects to monitor
Commitment root on DA layer, L1
Proof completion
Economics
TLDR
Alt-DA chains are typically subject to a PoS block-reward system which can introduce volatile pricing based on supply / demand
Ethereum / NEAR have gas models including computation, execution which introduces dependencies / competition within blocks
Celestia has a gas model more tuned to cost per byte vs. compute, which gives advantages
DAC committees have more flexibility and can offer a more stable pricing model similar to data storage (e.g. EigenDA and its flat rate)
Incentives for individual nodes to serve retrieval of data to provers is underdeveloped (most proofs are not live) and unaccounted for in incentive models unless proper slashing conditions are imposed
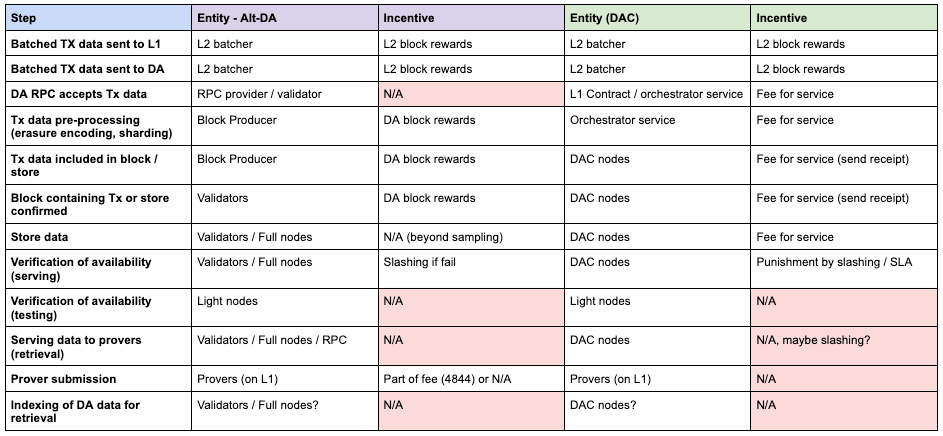
To understand how these DA systems behave over time we need to understand how their cost structure and incentives are derived, then map to actions that a user of a DA layer may want to complete. Building on the concept of “incentive completeness”, the general flow of a DA system has been outlined above, but it’s not yet clear how all the actors in this system participate and where they are incentivized to do so.
A big factor in any of these models is the tokenomics of the asset that the payments are denominated in. Given volatility of these assets, the price paid for DA can experience 2-3x shifts in times of high demand. As of now, there are limited options to hedge / smooth the cost of transaction.
Pricing structure
As we outlined above, DA layers primarily follow either the “Ordered DA” or “Data availability committee” architecture with some deviations / customization. These architectures imply certain economic models:
Auction model (Ordered DA) - price depends on the gas model of underlying chain and the balance of supply / demand for a limited blockspace
Metered billing (DAC) - pricing must sustain the cost of the nodes that participate in the network, typically based on the amount / types of data made available. Removing the fluctuating supply / demand component can offer more pricing predictability
There are slight differences in the implementation of either model, which we explore below.
Cost structure
Due to the decentralized nature of these DA layers, the primary cost of operation are born by the participants running clients (nodes / validators). Not including the ongoing development of the network, the “marginal” cost of running the network is roughly split into two segments:
Nodes / validators: independent (or self-hosted) participants who run software and perform core operations to secure and store the data. Ultimately this means incentives are required to cover the cost of all activities:
Hardware (fixed)
Write (ingress)
Storage
Read (egress)
Protocol overhead: Services and overhead of the network, can be provided by the governing body of the network itself or contracted out to 3rd parties
Light node sampling
RPC services
Indexing
Rewards for nodes/validators
Implications: All networks will need to ensure an economic model that is viable for all participants long term. The activities required must be incentivized explicitly or once scale / equilibrium is reached the non incentivized actions will not be performed.
Auction Model (Ordered DA)
DA chain solutions typically follow the Ethereum approach of an auction model or modified auction, which varies the cost per byte relative to the demand for space. This means the relative utilization / capacity of the underlying storage and changes to it can have a significant effect on the price of DA at any time. Auction-derived models underpin Ethereum, EIP-4844 (blobspace) and Celetia.
ETHEREUM
TLDR: the default / basis for many DA chain models, employing auction mechanics which leads to dynamic pricing
Ethereum’s transaction model was founded on concepts familiar to all blockchains:
Gas Model - an expense associated with various operations (e.g. storing in memory space, executing a transfer), set by the protocol
Auction Model - block builder chooses the set of transactions to include in a block that maximizes its economic value
The relative cost (gas) of operations is set by the protocol, however the user sets a price plus a “tip” for each unit of gas, such that an operator would accept their transaction into the next block. In the case of Data Availability, rollups primarily stored data in “calldata”, a cheaper read-only alternative to broader variable memory.
The important takeaway here - this is a relatively standard model for any chain-based DA layer, and implies an elastic pricing dictated by a market, governed by supply/demand balance.
The network upgrade EIP-1559 updated the gas model to introduce a “base fee” that is dynamically calculated based on the capacity of the previous block relative to a “target” utilization (in this case 50%). If the capacity is high, the base fee will be raised in the subsequent block and lowered as the capacity returns to the 50% capacity target. This has the effect of “smoothing” cost per block among other things - for more reading see the EIP-1559 github
However, the fee market is volatile because it shares the “auction space” with many transactions, not just data storage.
DA cost is a combination of transaction base fee, bytes of storage, and current demand
DA cost is volatile depending on demand for compute and storage (currently no flat rate pricing)
Ethereum L1 DA has a dependency on other transaction types, which may be more volatile or highly priced.
One option to fix this volatility is to dynamically adjust blocksize, but that is unlikely to happen on Ethereum since it would require protocol changes. Other options are to introduce separate fee markets for different transaction types (e.g. Solana’s local fee market design), which in part has led to the development of EIP-4844
ETHEREUM EIP-4844
TLDR: EIP-4844 has introduced a new side-space for storing ephemeral data with validators while putting a minimum commitment through consensus. This lowers cost but still has auction dynamics, and requires purchasing space in ~125kb increments.
Ethereum recently introduced a new type of transaction on the network, where a commitment to a larger “blob” of 125KB size is included in consensus while the blob data itself is stored with the validators. This introduces greater capacity for DA-specific transactions, which will be expanded via sharding in the planned Danksharding update.
Practically, there are two changes from a user perspective:
A separate fee market is introduced for blob transactions, so DA is not competing for space with execution and other transactions
A user much purchase the entire 4844 block regardless of if they will utilize the full block themselves, introducing a “cargo container” dynamic
4844 transactions lower the base gas fee on the transaction from 16 to 1, but still maintain an auction-style bidding system which introduces the potential for price volatility. The cost model includes several components in an end state:
Fee for inclusion in block for consensus
Fee for storage of bytes with node
Fee for submission of proof / bisection game
Not yet light node sampling or slashing conditions
CELESTIA
TLDR: Celestia also uses an auction model similar to pre-1559 Ethereum, however this model optimizes for bytes of storage and competes less with non-DA operations than Ethereum
Celestia uses a standard gas-priced prioritized mempool - it does not use a EIP-1559 system with a base fee. Celestia’s gas model is simplified relative to Ethereum, which allows it to optimize for a smaller set of actions specialized to Data Availability.
Celestia’s gas model is set based on a few primary components:
Fixed PFB (pay for blob) cost
Fixed gas cost per byte
Block size
If supply becomes constrained, the auction mechanism can possibly lead to spikes in pricing but Celestia can expand block size as well. Each of these constants that are fixed by governance (“Governance parameters”)
Important implications of the gas model today are:
Gas is not refunded if overallocated
There is no EIP-1559 style mechanism in place to smooth volatility in the case of demand spikes
Longer term, Celestia’s roadmap for based rollups implies that there will be shared blockspace between data availability and other transactions. There are other implications for using Celestia (and other non-ETH systems) for DA:
No explicit incentive for retrieval of data on a 1:1 basis
Cannot impose slashing conditions on the ETH network via light node sampling
AVAIL
Avail is pre-launch so we do not have as much information, but it appears to be following the same auction mechanism as Celestia.
METERED BILLING (DAC)
EIGEN DA
TLDR: EigenDA offers constant pricing per byte, which it pays out to Operators and a portion towards yield for re-staking.
EigenDA uses a model where ETH and other tokens (e.g. EIGEN) are staked to secure the storage of data in a set of off-chain nodes, where commitments are made back to the ETH L1. This functions under the broader AVS (actively validated services) model that Eigenlayer has pioneered, which has been well covered in other mediums (references here). This means that EigenDA is able to offer a fixed price for DA over a period of time similar to metered billing, because there is not an explicit auction model relative to Alt-DA chains.
The key entities in this model are:
DA Operators (storing the data): Paid via token inflation or fees generated from direct deals with DA customers. They stake collateral borrowed from the ETH mainnet pool, subject to slashing conditions for enforcing this behavior are not implemented but under development
Restaking providers: Lend capital to the operators to provide collateral, so the DA operators can accept DA deals and the fees associated. They are rewarded with a % yield on their restaked capital, which comes from some part of Operator revenue from deals and any token yield at a protocol level
Central orchestrators: Subsidized by token allocation by the Eigen Labs team to run centralized services
As of the writing of this article DA is free on EigenDA, but a steady state will need to find a balance of fees paid for services once the bootstrapping phase of the network is complete. This implies that:
Demand will need to pay for storage costs
DA Operators will need to generate sufficient returns that a premium can be paid to the restaked ETH for security
Cost of capital will compete the staked ETH against other AVS’
OTHER MODELS
NEAR
TLDR: NEAR utilizes block space to store data, similar to Ethereum base layer; this means auction model dynamics competing with other chain operations
NEAR DA appears to store data mainly in state, pushing some of that data storage externally via an on-chain commitment (e.g. merkle root) of fixed length. Essentially storing data from Ethereum state in NEAR state, taking advantage of the arbitrage between the cost / byte for each system.
There is no specific incentive model for this, it is looped in under the broader model for the NEAR chain where block rewards are accumulated, and the token price can go up or down based on demand for blockspace.
Summary
Two predominant designs for DA have emerged: Ordered DA utilizing on-chain storage verified by consensus and additional light node sampling for higher security guarantees, and DACs utilizing off-chain storage for higher scalability albeit with lower end-state security guarantees. However it’s critical to understand that the security differences often touted by these systems may not be fully implemented or even fully serving the needs of the end user if the cost of a failed transaction or withholding attack is not worth the price of additional security.
The primary security guarantee of both solutions relies on a consensus process (on-chain or otherwise) to impose slashing conditions on misbehaving nodes which has not yet been fully implemented. Perhaps most importantly, the incentives that maintain this security in the form of validator participation and staked security will need to be monitored careful to ensure they scale with the network beyond the initial bootstrapping phase.
For users, this creates an opaque selection process and the challenge of monitoring the ongoing development of these dynamic systems which, in a web2 context, would be a stable infrastructure layer. Fluctuating costs and security levels introduce new challenges for users looking to scale their products on these layers.
Looking forward, it’s important to consider the motivations for each of the “DA Layers” and how it impacts their function now and in future:
Ethereum: DA is a component of the system but not a primary focus. 4844 and danksharding will expand the capacity and serve to retain more transaction volume on the base chain
Celestia, Avail: DA is a first step in roadmaps to drive native transactions volume, but remains more of a core function of their solution than Ethereum. This will introduce complexity to the fee market.
Celestia plans for sovereign rollups to use their chain as a sequencing / DA layer - this has a greater value prop in that scenario
Avail plans to evolve into a transaction / proof aggregation and work towards the shared security layer
EigenDA: DA is a first product for their broader AVS system, bootstrapped to drive demand for EIGEN and other activity. It does not need to be economically viable near-term but rather act as a POC to bootstrap broader demand for EIGEN and their ecosystem
NEAR: DA started as an effort to drive more demand for their blockspace, but has been overshadowed by a recent pivot to AI. It remains to be seen if it remains a strategic priority
Arbitrum / zkporter: DA offerings exist to drive more usage and adoption for their users, who they monetize based off transactions / sequencing fees. It is a cost vs. profit center
In general, a theme is that DA is evolving to be a table-stakes offering with moderate commoditization - these DA layers will need to expand to broader feature sets to stay competitive, because the economics of DA alone may not be economically viable.
Fraud and Validity Proofs - deep dive
**This section of the article has been moved to it’s own post
Data Availability is not Data Storage
Data availability is often mischaracterized as equivalent or inclusive of data storage, when it should really be referred to as closer to “data publishing”. Marketing materials have claimed that DA will be used for AI, media, gaming etc. but often do not communicate it’s core usage - the short-term publishing of small-scale, immutable transaction data in a byzantine environment. This requires a specific set of design choices and imposes cost / performance tradeoffs.
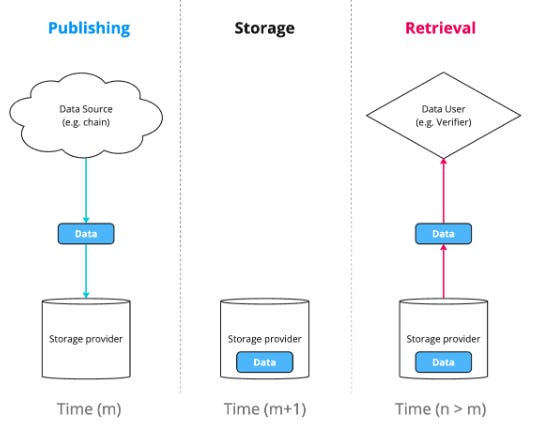
*Source: Data Availability vs. Data Storage, FilDev Denver ‘24
Data Availability Sampling ensures that data is distributed and accessible from a network of nodes, without specifying access patterns / redundancy etc. at an individual node level
Proof of Retrievals / Storage ensures that data is distributed and accessible from individual nodes with specified SLAs (retrievability, availability, replication / redundancy)
DA can be seen as a subset of Data Storage in the same way that large storage providers (e.g. AWS) have many tiers of storage that optimize for different scenarios like low-cost archival / disaster recovery, KV-stores, data lakes etc.
Design considerations
When comparing DA vs. decentralized storage, the tradeoffs become very clear in the proof systems employed and what they incentivize (via slashing or SLAs). Adding proof systems increases security if implemented correctly, but comes at the cost of additional processing and performance restrictions.
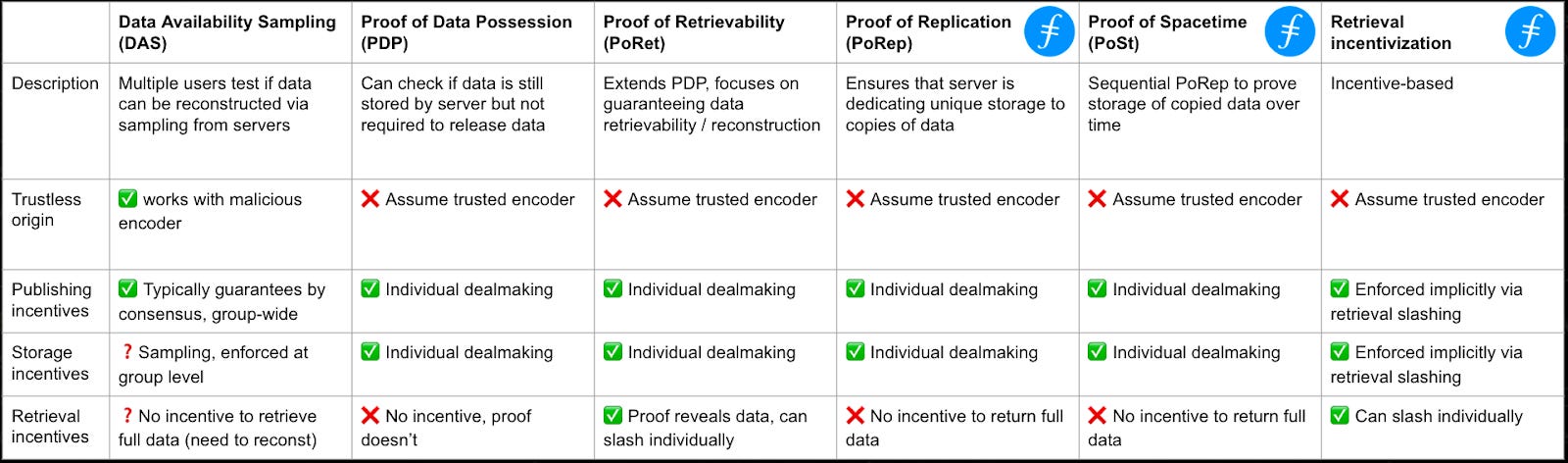
*Source: Data Availability vs. Data Storage, FilDev Denver ‘24
Storage is not a monolithic solution, choices need to be made around optimizing between:
Writes (ingress)
Storage cost
Retrieval (egress)
Overhead operations (e.g. indexing, worker jobs)
Security
In particular, Retrieval is a very complicated proof system for decentralized, permissionless systems which has not been elegantly solved. Proofs of latency / sampling are highly expensive (essentially require serving the full data every time) and can be hard to adjudicate where there are network delays or system failures. DA requires a one-time write of an immutable set of transaction data which may have varying indexing and processing needs.
Ordered DA vs. DAC
When comparing to databases the design choices of DA Chains vs. DACs becomes more stark. Ordered DA imposes global ordering and linearizability by virtue of using blockchains with consensus. Global ordering of the DA transactions is not necessarily needed because ordering and batching is handled at the rollup level - however this feature allows them to expand into new areas like sequencing.
DACs are more close to storage with a few additional guarantees on retrieval sampling. Operators essentially enter into short-term storage contracts and provide ongoing proof of data possession / retrieval depending on implementation. In order to impose any sort of slashing conditions on failed retrieval requires either a central adjudicator or a decentralized consensus process.
Economic models of storage
Learnings from decentralized storage networks have shown that without explicitly incentivizing any assumed action needed by participants in the system. We see from web2 storage solutions that services like Amazon dynamoDB often incur the greatest cost not on the writing and storage of the bytes, but on the worker operations and egress costs.
For a node to serve retrievals requires operating a service listening and serving incoming requests, and dedicating bandwidth. Additionally, retrieving the data requires indexing which is typically not built into the protocol base layer.
Where the DA vs. Data Storage divergence plays out
Right now there are presumed activities in DA networks that have not yet seen large-scale activity - for example the retrieval of data from participating nodes. This may work well at smaller scale, but functioning retrieval at scale is not perfectly solved (as previously discussed)
While DA systems are sub-scale and there are some level of perceived upside in being a good citizen (e.g. airdrops) we see many operations being given “for free” or as part of a block reward. However at scale the incentives need to be explicitly set
For a presentation that delves into this problem in detail from the lens of existing web3 storage solutions, see here: Filecoin Dev Presentation
Conclusion
We’ve covered a decent amount of detail on how DA systems work at their core in this article. In Part 3 we shift focus to the current empirical evidence of DA systems, and put forward some directions for DA systems and the industry as a whole to evolve in the future.